AI for Vision-Language Models in Medical Imaging (IN2107)
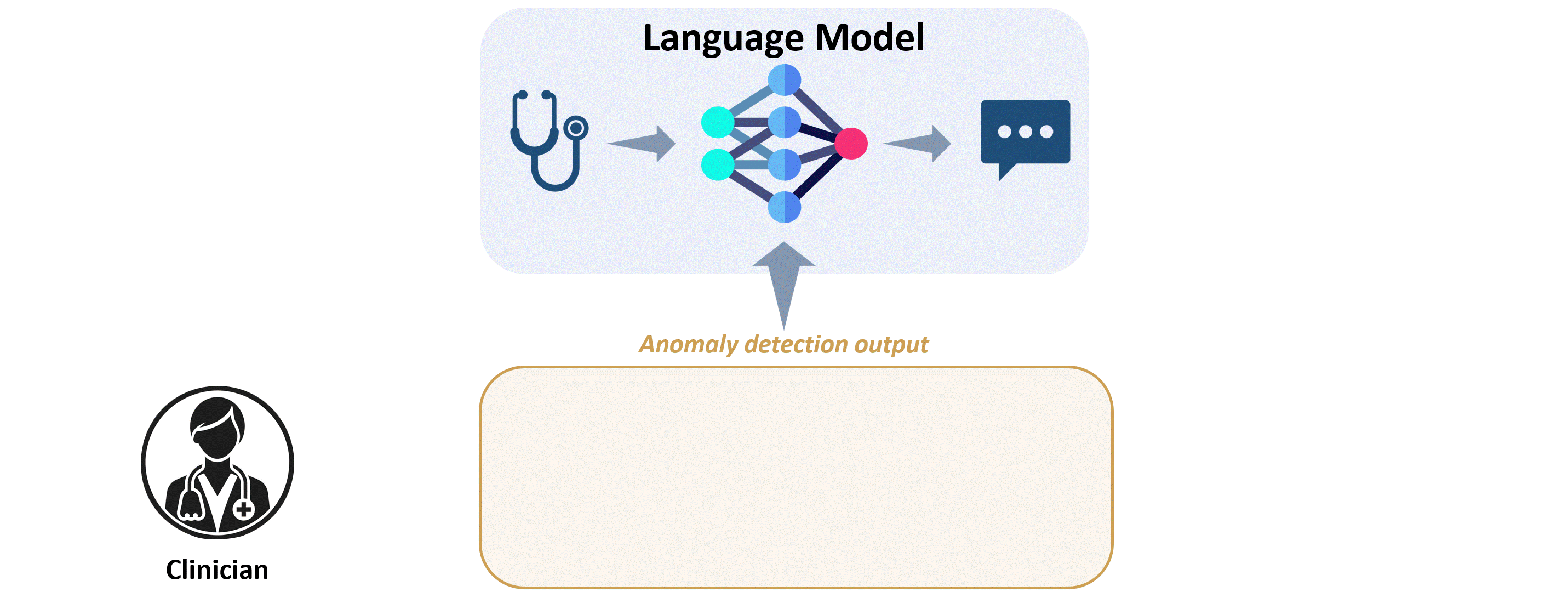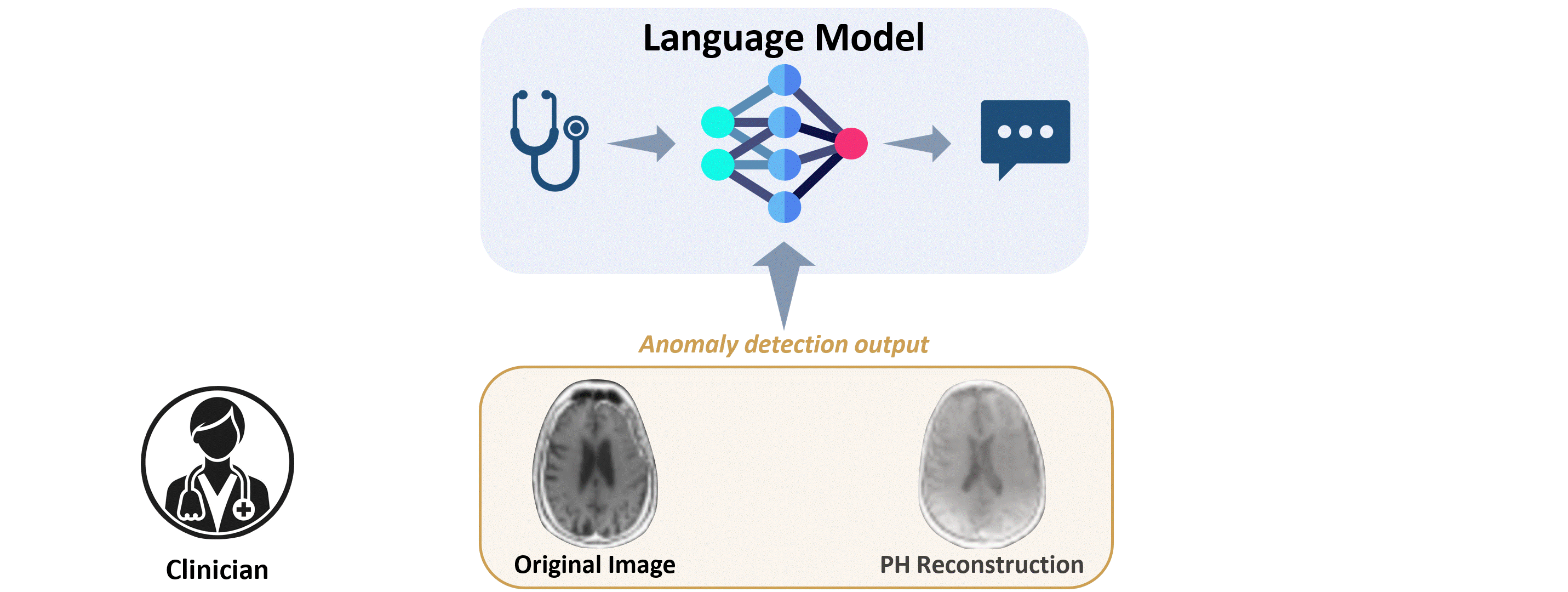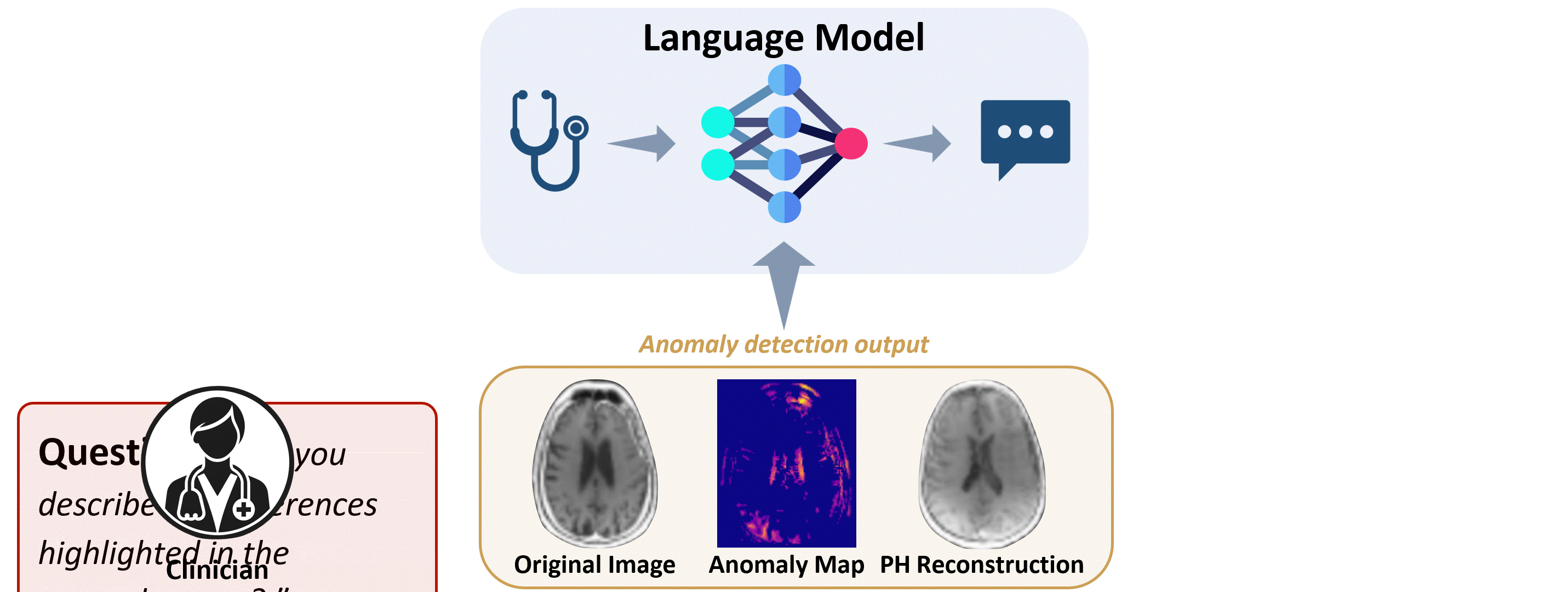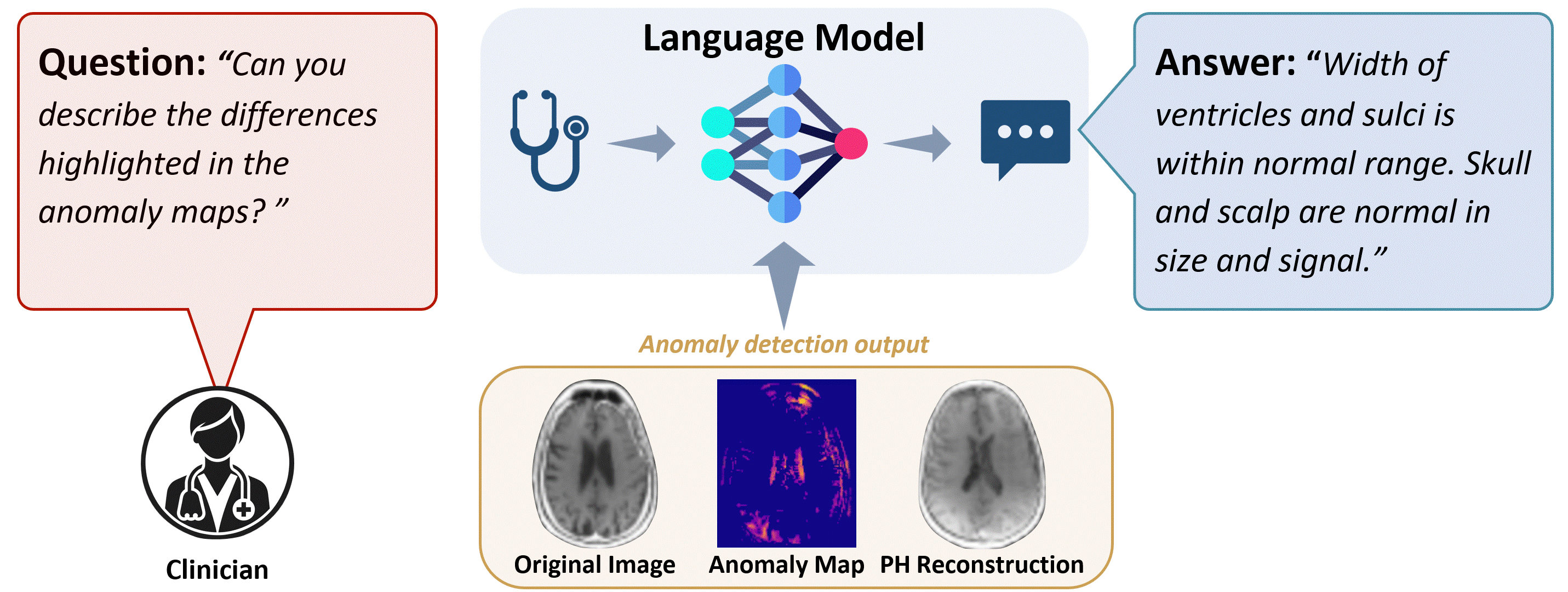
Time: Wednesday 14-16.
Location: - Garching (in-person): FMI, 5610.01.11 https://nav.tum.de/room/5610.01.011
- some invited talks on Zoom: https://tum-conf.zoom-x.de/my/cibercea?pwd=WlMvanU1NUcveUtjVTJrWHAzWFp1dz09
Vision-language models (VLMs) in medical imaging leverage the integration of visual data and textual information to enhance representation learning. These models can be pre-trained to improve representations, enabling a wide range of downstream applications. This seminar will explore foundational concepts, current methodologies, and recent advancements in applying vision-language models to diverse tasks in medical imaging, such as:
- Synthetic image synthesis
- Anomaly detection
- Clinical report generation
- Visual-question answering
- Classification
- Segmentation
Please register via the TUM matching system: https://matching.in.tum.de or write an e-mail to cosmin.bercea@tum.de
Check the intro slides here:
Cosmin I. Bercea
Research Scientist
I am a postdoctoral researcher specializing in vision and multimodal learning for medical image analysis, with the current focus on developing vision-language models for generative downstream tasks.
Jun Li
Doctoral Researcher
My research interests include Vision and Language, Multi-Modal Learning, and Cross-Modality Generation.